

The Lethal Trifecta of AI Agents: When Productivity Becomes Insider Risk

MIN
In June 2025, technologist Simon Willison coined the “lethal trifecta” for AI agents: the dangerous combination of access to private data, exposure to untrusted content, and the ability to communicate externally. His warning was simple: when all three exist in the same agentic workflow, a malicious instruction can move from content to action to data loss with alarming ease.
For security leaders, the lethal trifecta is not just a model security problem. It is an insider risk and AI security problem. It shows how delegated software can inherit human access, act on untrusted instructions, and move sensitive data before traditional controls know whether the action belonged to a person, a tool, or a compromised workflow.
AI agents are not just tools employees use. Increasingly, they are delegated actors. They read, reason, retrieve, summarize, write, execute, and communicate. They may operate through browsers, local endpoints, cloud services, messaging apps, code environments, or SaaS platforms. They often inherit the permissions of the user or system that launched them. And, crucially, they can turn a human request into a multi-step workflow faster than many security controls can classify, attribute, or contain it.
The difference between an AI tool and an AI agent is not just intelligence. It is agency. A chatbot may generate an answer. An agent may retrieve the data, choose the tool, take the action, and send the result.
What is the lethal trifecta?
The lethal trifecta forms when an AI agent has three capabilities in the same workflow:
1. Access to sensitive or private data
In an enterprise, this may include source code, legal documents, customer records, board materials, employee data, credentials, or files on local and mounted drives.
2. Exposure to untrusted content
This could be a web page, email, document, prompt, ticket, chat message, shared file, or external instruction. The risk is not limited to obviously malicious content. It can be buried in ordinary-looking material the agent is asked to process.
3. The ability to communicate externally
This may mean sending an email, uploading a file, posting to a service, calling an API, writing to a public location, or interacting with an external AI platform.
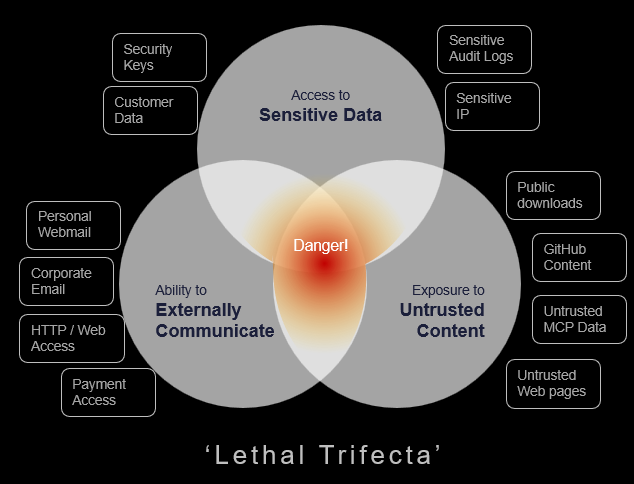
Individually, each capability is useful. Together, they create a pathway where an agent can be influenced by content, retrieve data it is allowed to access, and move that data somewhere the organization cannot govern. This is why AI agent security cannot be reduced to model behavior, prompt policy, or tool approval alone. It is a question of data access, autonomy, external action, and accountability operating in the same workflow.
Why the lethal trifecta creates a new AI insider risk
DTEX research shows that AI risk is becoming less about theoretical model behavior and more about everyday work: how employees access data, which tools they use, where they paste sensitive context, and whether security teams can see what happens next.
The Ponemon 2026 Cost of Insider Risks Report found that 92% of organizations say generative AI has changed how employees access and share information, while only 18% have fully integrated AI governance into insider risk programs. Seventy-three percent worry unauthorized AI use is creating invisible data exfiltration paths.
That gap matters because most AI-related insider risk is unlikely to begin with malicious intent. DTEX i³ observations point to a dominant pattern of well-intentioned employees optimizing for speed, not insiders deliberately trying to cause harm. But the same behaviors — uploading internal files, prompting with sensitive context, using personal accounts, or experimenting with unsanctioned agents — can create persistent data exposure when visibility and governance lag behind adoption.
AI agents intensify this because they expand the insider boundary. A user may start the task, but the agent may choose the steps, tools, paths, and destinations. In DTEX research on endpoint-based agents, locally executed AI agents were shown to access files, run commands, communicate with external AI services, and operate without continuous human interaction. Some could be configured through personal messaging apps such as Telegram or WhatsApp, creating a practical data exfiltration pathway that bypasses traditional assumptions about user-driven activity.
What the lethal trifecta looks like in practice
Consider three common enterprise scenarios.
- A product manager asks an AI browser to analyze customer feedback from internal spreadsheets. The agent uploads the data into an external AI service to complete the task. The employee wanted insight, not exposure, but sensitive content has moved outside approved controls.
- A developer uses an agent to troubleshoot a system issue. The agent reads local files and environment variables, encounters credentials, and includes them in logs, prompts, or outputs. DTEX research notes that agentic AI projects can expose credentials and API keys in process parameters, creating both an insider risk concern and a path to privilege misuse.
- A departing employee instructs an agentic browser to collect, compress, encrypt, rename, and send files through a personal webmail session. DTEX research on agentic browsers describes how these workflows can automate staging, obfuscation, and exfiltration while blending into ordinary endpoint and browser activity.
These examples are not science fiction. They are the natural result of giving software human-level access, machine-speed execution, and external communication paths without equivalent oversight.
Why attribution is the hardest problem in AI agent security
The hardest question is no longer simply, “Was this allowed?” It is, “Who or what actually did it?”
Was the action taken by the employee, the agent, another agent, a compromised workflow, or malicious instructions embedded in content?
This distinction matters. If an employee intentionally misuses an agent, the response is different from a case where a benign user is manipulated by a compromised or misdirected agent. Both may produce data loss. They do not require the same governance, investigation, or remediation.
Attribution also shapes how security teams respond. It affects incident response, policy enforcement, employee coaching, HR escalation, legal review, access control decisions, and forensic reconstruction. Without clear attribution, organizations may struggle to determine whether an incident was malicious, negligent, compromised, or machine-driven.
As agents begin to coordinate, the problem becomes harder. Agent-to-agent interaction can turn isolated failures into shared authority, influence, and amplification. One agent’s access, instructions, or outputs may influence another’s behavior, making it harder to isolate where human intent ended and delegated activity began.
Breaking the lethal trifecta
The goal is not to block AI agents. That will fail in most enterprises and may push usage further into the shadows. The goal is to prevent all three conditions — sensitive data access, untrusted input, and external communication — from aligning without oversight.
Security teams should start with a simple operating question: where can an agent access sensitive data, process untrusted content, and send information outside approved controls? From there, they should assess whether they can see the full workflow: prompts, tool calls, file access, command execution, browser activity, credential exposure, and outbound movement. They should also determine whether actions can be attributed to a human, an agent, another agent, or a compromised workflow.
Controls should focus on governing the workflow, not just approving the tool. That means applying least privilege to users and agents, restricting unnecessary scripting or command-line access, reviewing access to credentials, local files, mounted drives, personal webmail, external AI platforms, and unmanaged destinations, and ensuring AI agent activity is included in insider risk investigations and tabletop exercises.
The next evolution is supervised autonomy: systems that monitor agent behavior, enforce boundaries, attribute actions, and intervene when activity crosses risk thresholds. This is where Guardian Agents become important — not as automation for its own sake, but as a way to provide visibility, enforce data-aware controls, support attribution, and help security teams separate useful automation from risky behavior before productivity becomes exposure.
What security leaders should do next
The lethal trifecta is useful because it turns a complex AI security problem into a clear operating question: where in our environment can an agent access sensitive data, ingest untrusted content, and communicate externally?
A stronger question follows: where have we delegated authority without matching visibility, attribution, and control?
That question belongs in AI governance reviews, insider risk programs, DLP strategy, endpoint visibility planning, SaaS onboarding, and executive risk discussions. It also belongs in tabletop exercises, because agentic incidents will challenge traditional assumptions about intent, identity, and control.
AI agents are fast becoming part of enterprise work. The organizations that succeed will not be the ones that ban them longest. They will be the ones that understand how human intent, agent authority, data access, and external action intersect — and build controls before productivity becomes exposure.
See how DTEX helps organizations bring visibility, attribution, and control to human-agent workflows — before automation creates unseen exposure.
FAQ: the lethal trifecta
The lethal trifecta occurs when an AI agent can access sensitive data, process untrusted content, and communicate externally within the same workflow. When these three conditions align, a malicious or hidden instruction can potentially influence the agent, trigger access to private data, and move that data outside approved controls.
The lethal trifecta creates insider risk because AI agents often operate with user or system permissions. If an agent can act on behalf of a user, access sensitive information, and communicate externally, the organization may struggle to determine whether an action was taken by the employee, the agent, another agent, or a compromised workflow.
Organizations can reduce AI agent risk by limiting agent permissions, monitoring prompts and actions, controlling outbound channels, reviewing access to sensitive data, detecting credential exposure, validating approved use cases, and building attribution into AI governance and insider risk programs.
AI can accelerate insider risk by helping users automate reconnaissance, data staging, and transfers at machine speed while still acting through legitimate access. That makes risky behavior harder to distinguish from normal work unless teams can see the broader pattern.
Topics
Subscribe today to stay informed and get regular updates from DTEX