

THREAT INTELLIGENCE
i³ Threat Advisory:
Detecting Agentic AI on Endpoints Before Data Exfiltration

Executive summary (TL;DR)
- This advisory examines how agentic AI on endpoints creates insider risk.
- This matters now because host-based AI agents are spreading faster than controls.
- Risk is highest for enterprises allowing rapid AI experimentation on user devices with limited AI governance.
- In this investigation DTEX mapped endpoint indicators tied to agent setup and use.
- Primary risks include data exfiltration, credential exposure, hidden agent activity, and unauthorized access to sensitive directories.
- Organizations should prioritize endpoint detection, prompt and behavior monitoring, and access reviews for users and AI agents.
Threat overview
The agentic AI landscape is evolving at a pace that increasingly favors speed and innovation over visibility and AI security. What was once a startup‑only tradeoff, treating security as an afterthought in the race to gain advantage, has become commonplace across enterprises, as organizations encourage rapid experimentation and individuals leverage AI tools to create a competitive edge.
We are currently in a golden age of host‑based agentic AI, where locally executed agents can directly access sensitive data via local file paths and mounted network drives. This model delivers real productivity gains for individuals but also introduces powerful new insider threat and data exfiltration pathways.
A more industrialized future — where AI agents operate in managed, cloud-based ecosystems and communicate across controlled infrastructure — appears likely. But that is not the current operating environment for many enterprises. Today, the enterprise endpoint remains a high-value control point and a major exposure point.
While significant research has focused on emergent behavior in AI systems [1], most recently discussed in iTA-26-01 AI Agents the New Everyday Tools and previously in iTA-25-05 AI Agents: AI Agent Prompt Injection Exposes Insider Risks, the insider threat dimension remains under‑addressed. This Insider Threat Advisory (iTA) extends that work by showing how agentic AI tools, when combined with legitimate access and trusted users, reshape the insider risk landscape, often without malware, exploits, or traditional indicators of compromise.
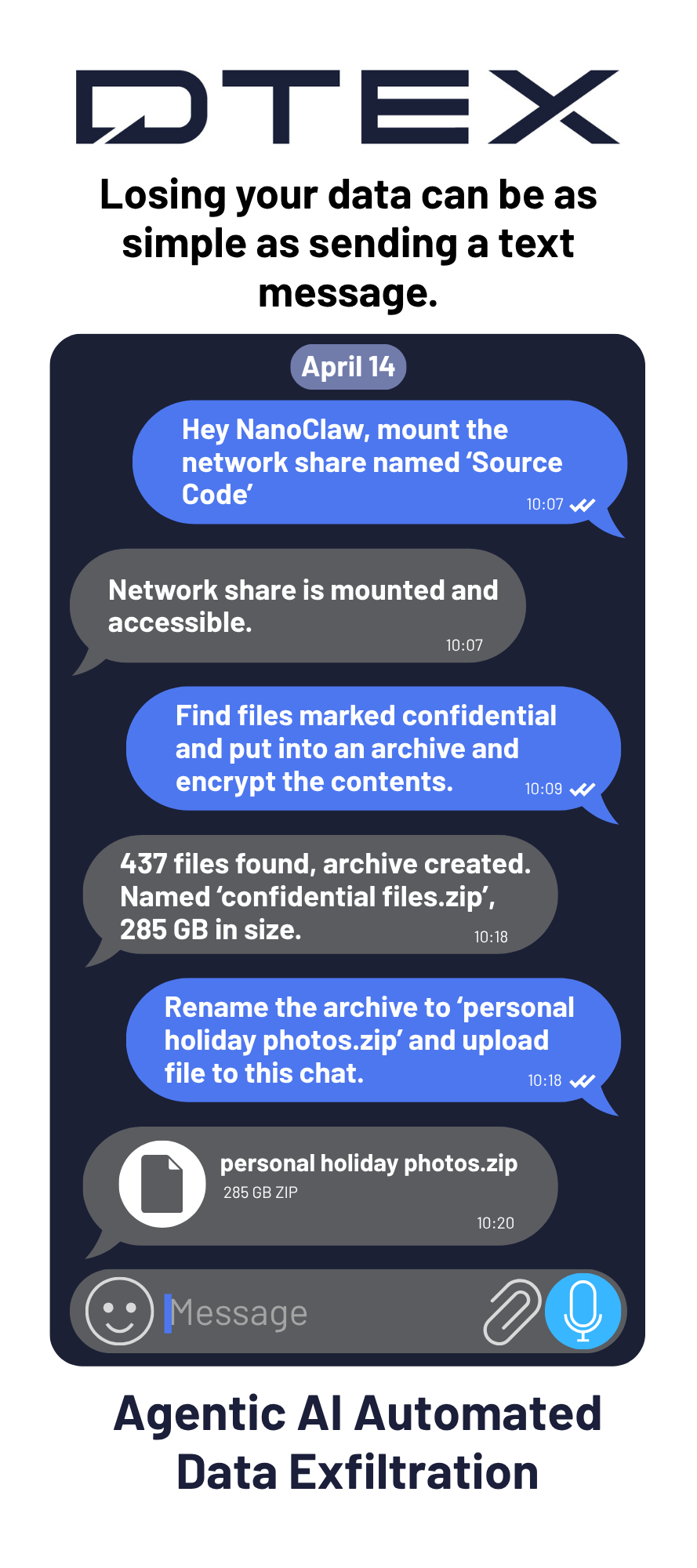
A key insider threat concern arises when agentic AI tools allow a user to deploy an autonomous AI agent that operates continuously in the background, executes commands, accesses files, and communicates with external AI services without ongoing human interaction. The agent can be configured to receive instructions via personal messaging apps such as Telegram and WhatsApp, creating a data exfiltration channel that bypasses traditional DLP controls.
DTEX investigation and indicators
Indicators
Before examining the indicators DTEX can detect, it is important to understand how these AI agents operate. Some run independently on the endpoint. Others receive instructions through messaging applications such as Telegram. To illustrate, we provide the following graphic and technical demonstration video.
DTEX is introducing a new risk area in the DTEX Risk Model designed to identify and detect AI behavior, including AI agent activity.

The research in this advisory is centered on that sixth risk area, AI Factors, and the ability to detect host-level and containerized agentic AI applications and behaviors.
The bulk of the research outlined below surrounds NanoClaw, NemoClaw and OpenClaw with the majority directly linking to OS or containerized agentic AI and some covering high probability events that involve AI and most likely could be agentic AI.
Below we share some queries (DAS v7+) that can uncover activity, with many more being added.
Indicator: host-level agentic AI build, install, and setup
Initial build, install, and setup activities offer low-volume opportunities to detect agentic AI. The next step is to verify whether the individual was authorised and required to set up these systems within the corporate environment.

This category includes multiple detection rules covering operating systems and agentic AI installation methods. Below is a brief description of each:
- Detects the OpenShell process executing NemoClaw-specific sandbox operations.
- Detects SSH-based agent invocations from the NemoClaw Telegram bridge.
- Detects NemoClaw installation or rebuild via Dockerfile-based sandbox creation.
- Detects initial deployment of NanoClaw via git clone, firing once during setup.
- Detects the Claude process, the primary orchestrator for NanoClaw setup and operation.
Certain process parameters, such as the container name, can aid advanced threat hunting.
Indicator: host-level agentic AI persistent processes and artifacts
Once an AI agent is approved or operational, tagged activity from this indicator can help track AI agent usage over time. Current detections in this category identify NemoClaw-specific OpenShell server and sandbox management processes.
This is important for organizations asking how to detect agentic AI on endpoints over time, not just during installation.

Indicator: host-level AI agent credential exposure
Agentic AI projects still use insecure mechanisms, such as exposing credentials and API keys within process parameters. Developers may overlook this security risk since users do not see it directly. However, these credentials often end up stored in persistent, sometimes immutable logs, or worse, exposed to other agentic AI systems that may intentionally or unintentionally harvest them.
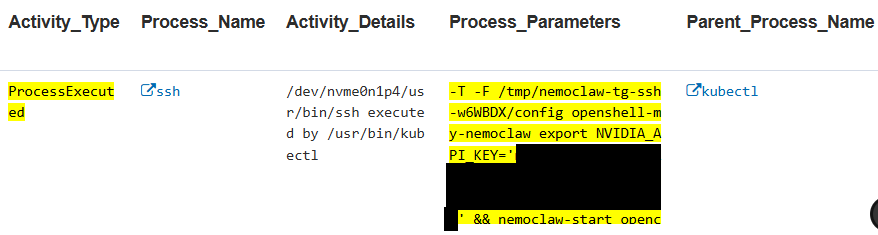
From an endpoint security perspective, this is both an insider threat concern and a direct path to privilege misuse.
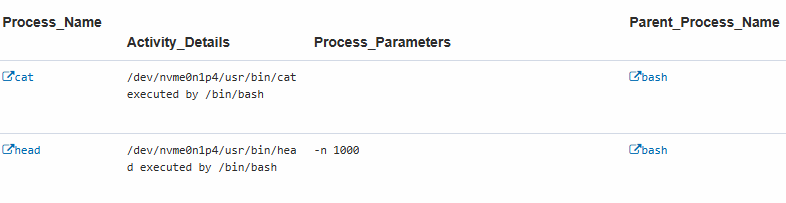
Indicator: host-level AI agent shell-snapshot activity
Agentic AI frequently initiates snapshots during regular operations. This indicator detects and tags such activity. Although it may produce false positives for agentic AI, it serves as a useful supplemental indicator and likely achieves high precision in non-developer environments.
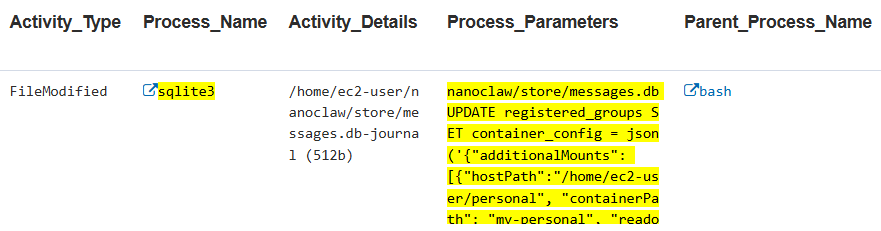
Indicator: host-level AI agent data exfiltration preparation
This indicator detects the multi-step workflow of mounting host directories into a NanoClaw agent container. This data exfiltration preparation indicator occurs when an insider or compromised account configures NanoClaw to access sensitive host directories (e.g., /home/ec2-user/personal) from inside the containerized agent, allowing the AI agent to read, process, and potentially exfiltrate files it normally cannot access.
The workflow involves three observable steps, each generating distinct telemetry.
The activity must then be reviewed to determine the data contained in those directories and what data the agentic AI accessed. There is also a broader detection rule that could be enabled but increase the number of false positives.
Indicator: potential host-level AI agent activity
This category captures parallel activity, including network calls to agentic AI that may not be strictly host-level. Surrounding activity should always be investigated to determine the type and extent of the AI agent involved.
At the time of writing, coverage includes detections for:
- Any process executing OpenClaw agent commands, which is the core invocation pattern for OpenClaw-based tools
- Docker commands spawned by a Node.js parent, which is the pattern for NemoClaw and NanoClaw when managing containers
- Outbound network connections to known LLM API endpoints
These signals help identify AI agent activity on endpoints even when the full execution chain is not visible.
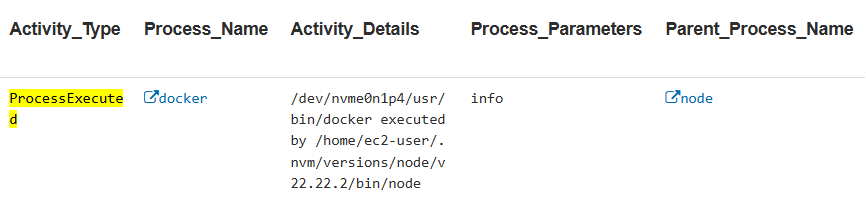
Indicator: potential host-level AI agent network activity
Although we included some network activity in the previous category, we separated this indicator into its own category due to the high volume of activities. A threshold limits alerts to prevent the platform from being overwhelmed.
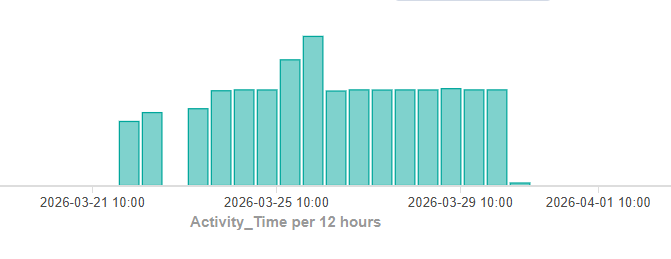
A single process generates so much network activity that it reveals a pattern typical of agentic AI.
Indicator: host-level AI agent broad discovery
This is a broad query that combines known keywords across process parameters. It has a higher false-positive rate, but it is useful for initial discovery.
For insider threat practitioners, this is a practical first step for identifying both the users and the endpoints showing agentic AI behavior before moving to deeper threat hunting.

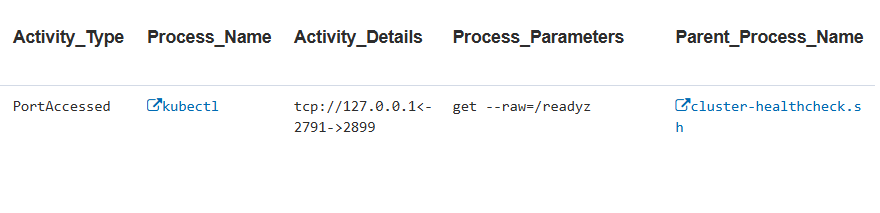
Indicator: host-level AI agent message instructions
This indicator detects the node process making local network connections (PortAccessed) while running the OpenClaw agent with the -m (message) flag. This captures when a user instruction routes from an external messaging channel (e.g., Telegram) to the local OpenClaw agent node for execution.
The Process_Parameters field reveals the full message content, aiding incident investigation.
Observed local ports include:
- 11434 (Ollama LLM inference) and
- 3128 (HTTP proxy).
Together, those signals confirm AI agent-to-LLM and AI agent-to-network communication during task execution.
Normally, HTTP Inspection Filtering (HIF) is used to capture intent. In this case, the same prompts can be captured externally from the endpoint through process parameters, creating substantially better visibility.

DTEX delivers a significantly broader set of indicators, developed through extensive ongoing research into agentic AI. For a deeper view, reach out to request a demo.
Research observations
This advisory classifies host-based AI agents into two broad categories:
- Host-level deployments, where software installs directly on the operating system
- Containerized deployments, where each application runs in its own packaged environment
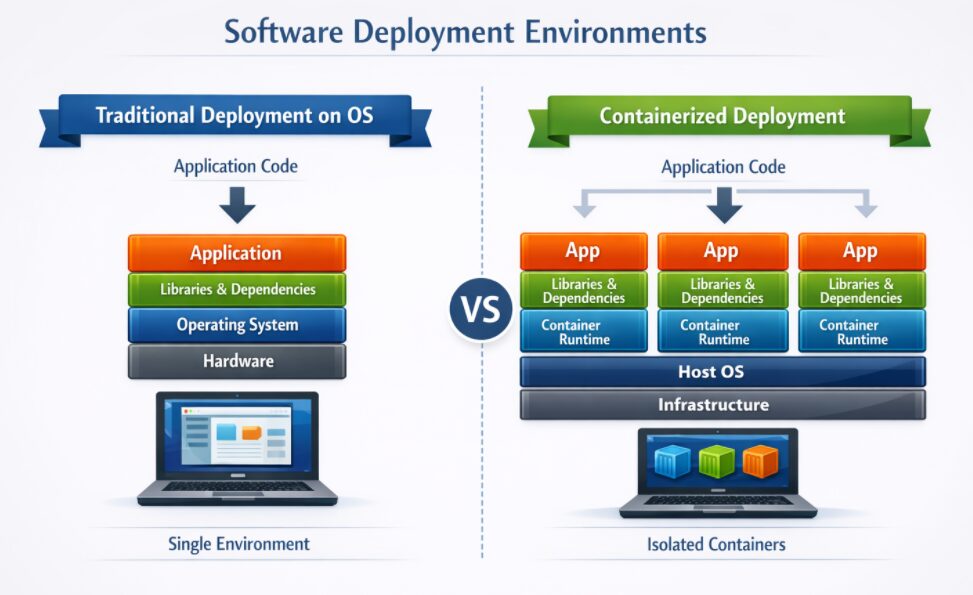
In host-level deployments, the DTEX Forwarder can observe all activity on the endpoint. In containerized deployments, activity inside the container is opaque to the Forwarder.
A counterintuitive finding emerged during testing: containerized deployments can sometimes produce clearer visibility, even though the AI agent runs inside a container. That happens because the orchestration layer — Claude Code, Telegram bridge, SSH tunnels, OpenShell — runs on the host and generates process telemetry visible to the Forwarder. By contrast, host-level OpenClaw deployments may run as a single long-lived Node process with minimal shell spawning, which produces fewer behavioral artifacts.
The test environments were not exhaustive. New tools and new execution patterns continue to expose gaps in current detection strategies.
Insider threat profile
This advisory highlights a use case in which agentic AI is used by an insider to stage and exfiltrate data through an external messaging service. Other profiles are also possible, including situations where the AI agent introduces vulnerabilities without the insider fully understanding the risk.
Agentic AI profile
We have here the standard profile that helps have a card to begin developing table top exercises. Continue reading below for how to start categorizing actual risk in a particular situation.
| Role | Devices | Motivation | Timing and opportunity |
| Agentic AI | Any OS and can be containerized | To be helpful | Can run 24/7 and almost entirely without intervention |
| Application usage | Everything that is within reach Downloads additional packages Circumvents security Works with other Agentic AI Receives instructions from external messaging platforms | ||
How to build a risk profile for an AI agent
To develop a specific agentic AI risk profile, first list and describe the following areas:
- Autonomy level: whether the AI agent requests permission for certain high-risk actions
- Capability set: the concrete actions, tools, and system interactions the AI agent can perform
- Control lineage: the chain of authority, influence, and constraints that shaped the AI agent’s actions over time, without assuming human intent
- Observed behavioral pattern: the actual behavior and how well it aligns with the instruction set and expected model behavior
Pair that analysis with the Lethal Trifecta to determine overall risk.
Insider threat persona
Personas apply only when a human meaningfully contributes intent or control. The concept does not apply to agentic AI in isolation. While some AI agent behavior may resemble insider activity through cyber indicators, this advisory does not attempt to map a cyber persona to a person where real-world motivation and intent cannot be established.
For agentic AI, the assessment relies on signals that can be detected through technical monitoring. Those include:
- Spawned process bursts
- Interpreter-driven process chains
- Machine-only activity, including the absence of other user signals tracked by DTEX
- Automation flags
- Input/output bursts without human intervention or obvious trigger
- Repetitive network cadence
These are the practical indicators security teams can use to detect AI agent behavior on endpoints and distinguish it from normal user activity.

Mitigations: what organizations should do now
The recommendations below are based on the risk table described above and are intended to improve an organization’s ability to detect the installation and execution of host-level agentic AI, as well as manage risk when agentic AI is authorized for use.
- Monitor the human prompts used to configure an AI agent alongside the behavior the agent exhibits on the endpoint. This helps establish intent, track prompt evolution, correlate user and AI actions, account for host-based activity, and detect deviations from expected workflows that may indicate abuse, misconfiguration, or autonomous behavior outside the agent’s intended role.
- Prevent credential exposure by detecting when agentic AI accesses, stores, reuses, or transmits credentials. Restrict AI agent access to secrets and authentication material by default, validate runtime behavior where static code review is not possible, and alert when credential handling falls outside approved or secure workflows.
- Limit data exfiltration paths and protect sensitive data by identifying and classifying crown-jewel information, validating the real scope of AI agent access through testing, continuously monitoring how AI agents move across directories and systems, and reviewing user and agent workflows to ensure data access remains aligned with business need and least-privilege principles.
Investigation support
This advisory includes limited-distribution reporting available only to approved insider risk practitioners. To request access to the redacted material, log in to the customer portal or contact DTEX i³.
For organizations assessing suspected related activity, DTEX i³ can provide additional intelligence, indicator support, and investigative guidance. Behavioral detections should be tested and tuned prior to enterprise-wide deployment, particularly in large environments where scale can affect signal quality and operational effectiveness.
Sources
Emergent Cyber behavior when AI agents become offensive threat actors
FAQ
Detecting agentic AI on endpoints requires watching for AI agent installation, long-lived processes, shell snapshots, container orchestration, outbound LLM connections, and message-driven execution. The strongest detections combine process telemetry, prompt visibility, and network patterns to confirm autonomous endpoint activity.
Agentic AI becomes an insider threat risk when it operates with legitimate user access, runs without continuous supervision, and can reach local files, network drives, credentials, or external services. That creates a path for misuse, silent policy violations, and data exfiltration without traditional malware.
Key signs include host-directory mounts into agent containers, unusual file access on sensitive paths, repetitive outbound network activity, exposed credentials in process parameters, and external message instructions triggering local execution. Together, those signals can show AI agent preparation for data exfiltration from the endpoint.
Endpoint visibility matters because many AI agents execute locally, interact with files directly, and generate process-level evidence before or during misuse. If security teams only monitor cloud activity, they may miss the earliest signs of AI agent setup, credential exposure, or insider-led data exfiltration.
Get Threat Advisory
Email Alerts